

強調表示されたコンテンツWEBパーツはタイトルやコンテンツの内容、作成者や更新者名でフィルターすることが可能です。
その他の項目でコンテンツを抽出したい場合は「管理プロパティ」を使うことで実現可能な場合があります。
今回はこの管理プロパティを使用したコンテンツの抽出方法について仕様なども含めまとめていきます。
管理プロパティとは
SharePointでは検索エンジンによりクロールされた様々なプロパティを管理プロパティにマッピングし、WEBパーツやAPIなどから利用できるようにしています。
以下、Microsoftから案内されている管理プロパティの概要及びマッピングの一覧です。

独自にサイト列を作成した場合、自動で管理プロパティが作成されサイト列にマッピングされます。
今回の例ではサイト列として「TenantDocumentCategory」を作成しました。
テナントにサイト列を作成する方法についてはこちらの記事を参考にしてください。

サイト列を作成すると自動で「TenantDocumentCategoryOWSCHCS」という管理プロパティが作成されました。
では、この管理プロパティでフィルターしてみます。
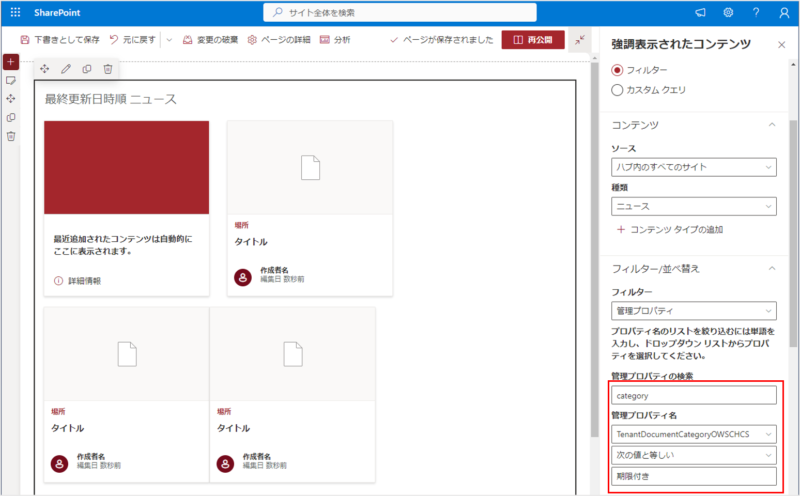
この管理プロパティには「期限付き」という完全一致の文字列が入力されている記事があるはずなのですが、うまく抽出してくれません。
抽出されるべき記事はこちら。
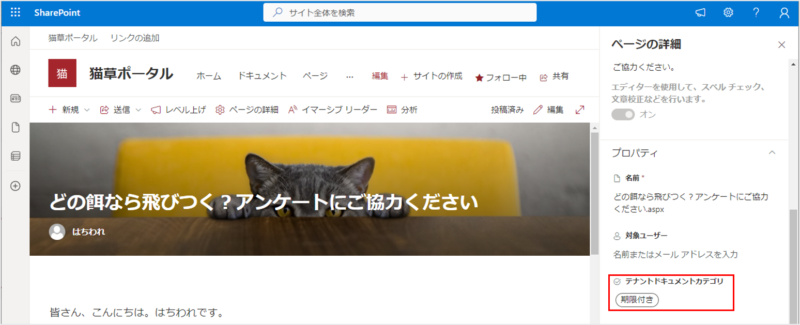
なぜヒットしないのでしょう?
ワードブレーカーについて
前述の通り、管理プロパティはSharePointの検索システムによりクロールされたプロパティの値です。
強調表示されたコンテンツWEBパーツで管理プロパティを指定した場合、実際には検索ボックスから検索を行うのと同じ処理がバックグラウンドで行われます。
したがって、クロール処理が終了していなかったりエラーになっていたりした場合、抽出から漏れてしまいます。
また、SharePointの検索システムではクロールされた情報が「ワードブレーカー」というモジュールにより単語に分割されます。
例えば「期限付き」という文字列は「期限付き」でインデックス化されるわけではなく、「期限」と「付き」というトークンに分割されます。
これはどういうことかというと「期限付き」という文字列での検索ではヒットせず、「期限」や「付き」単体の検索ならヒットするという動きになります。
前項でうまくフィルターしてくれなかったのはこれが原因なのですね。
ワードブレーカーで用いられている形態素解析の技術は、機械翻訳や文字列抽出、校正支援など様々な自然言語処理を応用したアプリケーションで利用されている一般的な言語解析アルゴリズムとなります。
複雑な日本語では、文章内の句読点や文字の並びなどの影響により、抽出(分割)される文字列が使用者の期待どおりにならないことがあります。
日本語難しいですからね 汗
以下はSharePointの検索アーキテクチャに関するMicrosoftの記事になります。
SharePoint2010向けの少し古い情報ですが、SharePointの検索の仕組みについて詳しく書かれています。
フィルター条件の「次の値と等しい」はワードブレーカーを意識する
ワードブレーカーにより分割されてしまう以上、今回の例でいう「期限付き」に等しいという条件ではヒットしないということになります。
ならどうすれば良いか。
ワードブレーカーによる分割結果に従い「期限」and「付き」という条件で抽出していくしかありません。
例えばこんな感じで「管理␣付き」のように条件を入力します。
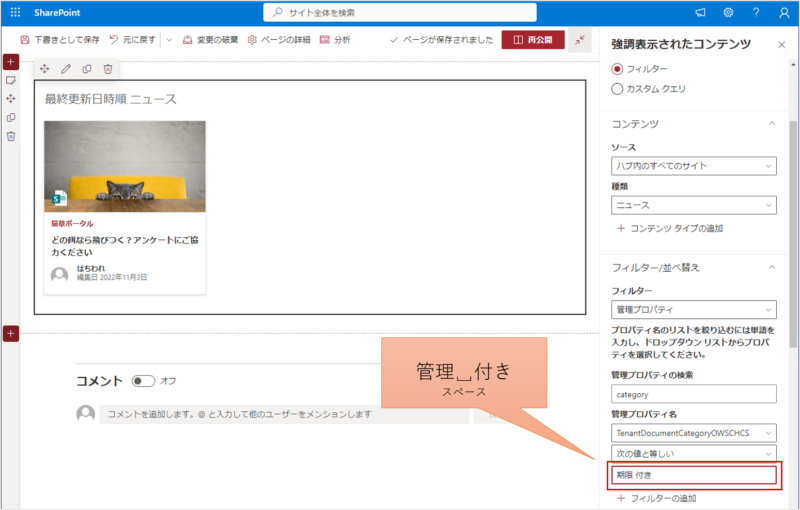
該当する記事が抽出されました。
管理プロパティが検索アルゴリズムを使用すること及び検索のアルゴリズムの仕様を知らないとわかりえない裏技ですね 汗
まとめ
いかがでしたでしょうか。
一見オールマイティに使えそうな管理プロパティにはちょっと厄介な仕様があるよというご紹介でした。

コメント